Shiyu Huang 黄世宇Researcher, XPENG
Haidian District, Beijing, China, 100084.
[OpenRL] [知乎] [Google Scholar] [GitHub] [Linkedin] [CV] Visitors: 17012 |

|
Biography
I am a principal researcher at XPeng Inc. Before that, I worked as a principal researcher
in Zhipu AI and 4Paradigm Inc., and I am the leader of the OpenRL Lab. I received my B.E. and Ph.D. degrees
(co-advised by Prof. Jun
Zhu and Prof. Ting
Chen) from
the Department of Computer Science and Technology, Tsinghua University in
July, 2017 and June, 2022.
My researches focus on visual language model(VLM), computer vision, GUI Agent, deep reinforcement learning, robotics, artificial general intelligence (AGI) and generative artificial intelligence
(GAI).
I have also spent time working at
RealAI Inc. ,
Huawei Noah's Ark Lab,
Tencent AI Lab,
Carnegie Mellon University
and Sensetime Inc. . And I am also the founder of the
OpenRL Lab(
Publications && Preprints
(* equal contribution)-
ME-IGM: Individual-Global-Max in Maximum Entropy Multi-Agent Reinforcement Learning
Wentse Chen, Yuxuan Li, Shiyu Huang, Jiayu Chen, Jeff Schneider
he 25th International Conference on Autonomous Agents and Multi-Agent Systems(AAMAS), 2026
[PDF] [BibTeX]@inproceedings{chenme, title={ME-IGM: Individual-Global-Max in Maximum Entropy Multi-Agent Reinforcement Learning}, author={Chen, Wentse and Li, Yuxuan and Huang, Shiyu and Chen, Jiayu and Schneider, Jeff}, booktitle={The 25th International Conference on Autonomous Agents and Multi-Agent Systems} }
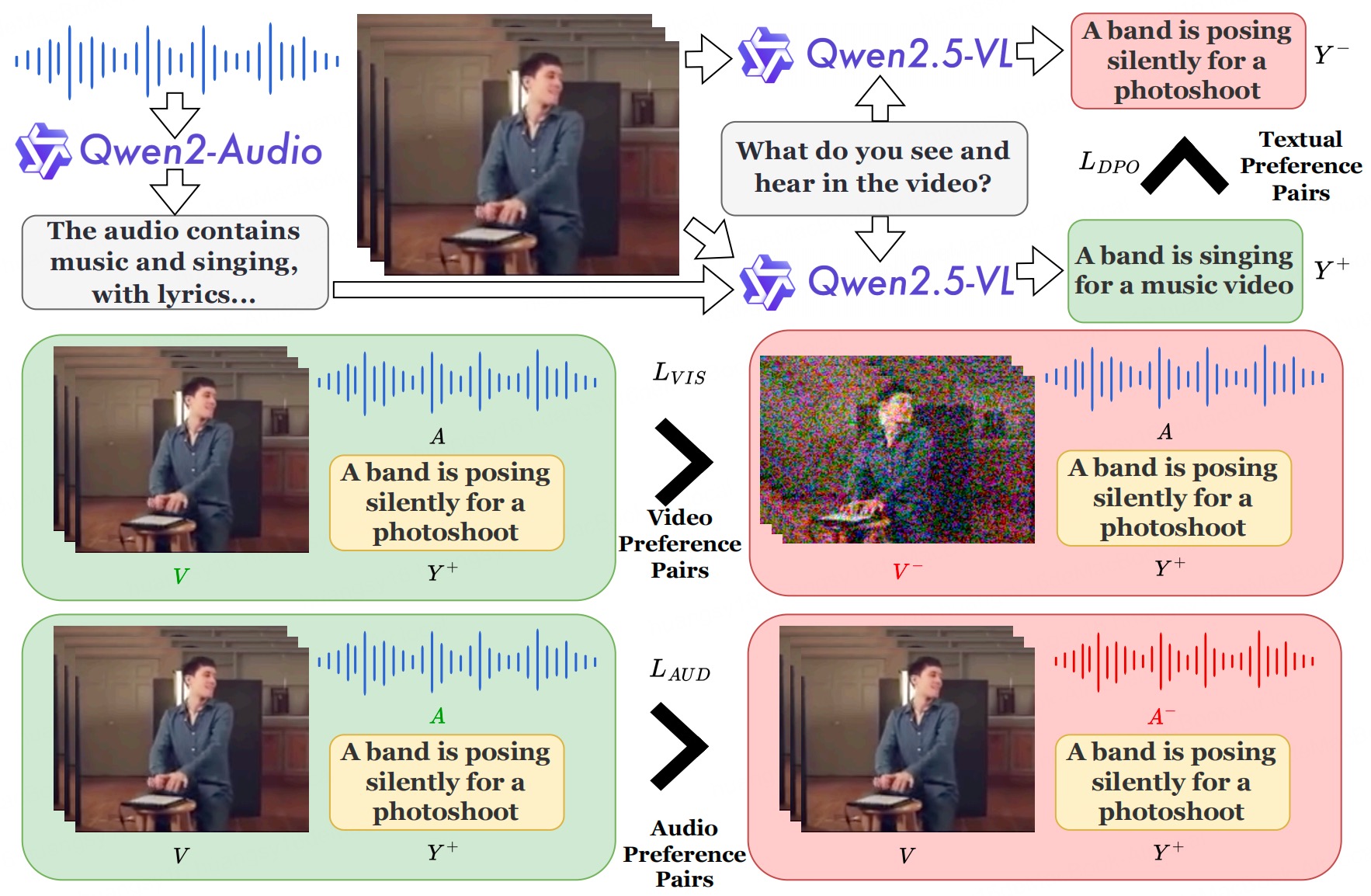
Junzhe Chen, Tianshu Zhang, Shiyu Huang, Yuwei Niu, Chao Sun, Rongzhou Zhang, Guanyu Zhou, Lijie Wen, Xuming Hu
The Fortieth AAAI Conference on Artificial Intelligence(AAAI), 2026
[PDF] [BibTeX]
@article{chen2025omnidpo, title={OmniDPO: A Preference Optimization Framework to Address Omni-Modal Hallucination}, author={Chen, Junzhe and Zhang, Tianshu and Huang, Shiyu and Niu, Yuwei and Sun, Chao and Zhang, Rongzhou and Zhou, Guanyu and Wen, Lijie and Hu, Xuming}, journal={arXiv preprint arXiv:2509.00723}, year={2025} }
-
Can Large Language Models Master Complex Card Games?
Wei Wang, Fuqing Bie, Junzhe Chen, Dan Zhang, Shiyu Huang, Evgeny Kharlamov, Jie Tang
The Thirty-Ninth Annual Conference on Neural Information Processing Systems(NeurIPS), 2025
[PDF] [Code] [BibTeX]@misc{wang2025largelanguagemodelsmaster, title={Can Large Language Models Master Complex Card Games?}, author={Wei Wang and Fuqing Bie and Junzhe Chen and Dan Zhang and Shiyu Huang and Evgeny Kharlamov and Jie Tang}, year={2025}, eprint={2509.01328}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2509.01328}, }

-
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Lingzhe Zhang*, Liancheng Fang*, Chiming Duan*, Minghua He*, Leyi Pan*, Pei Xiao, Shiyu Huang, Yunpeng Zhai, Xuming Hu, Philip S. Yu, Aiwei Liu
arXiv:2508.08712, 2025
[PDF] [GitHub] [BibTeX]@misc{zhang2025surveyparalleltextgeneration, title={A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models}, author={Lingzhe Zhang and Liancheng Fang and Chiming Duan and Minghua He and Leyi Pan and Pei Xiao and Shiyu Huang and Yunpeng Zhai and Xuming Hu and Philip S. Yu and Aiwei Liu}, year={2025}, eprint={2508.08712}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2508.08712}, }

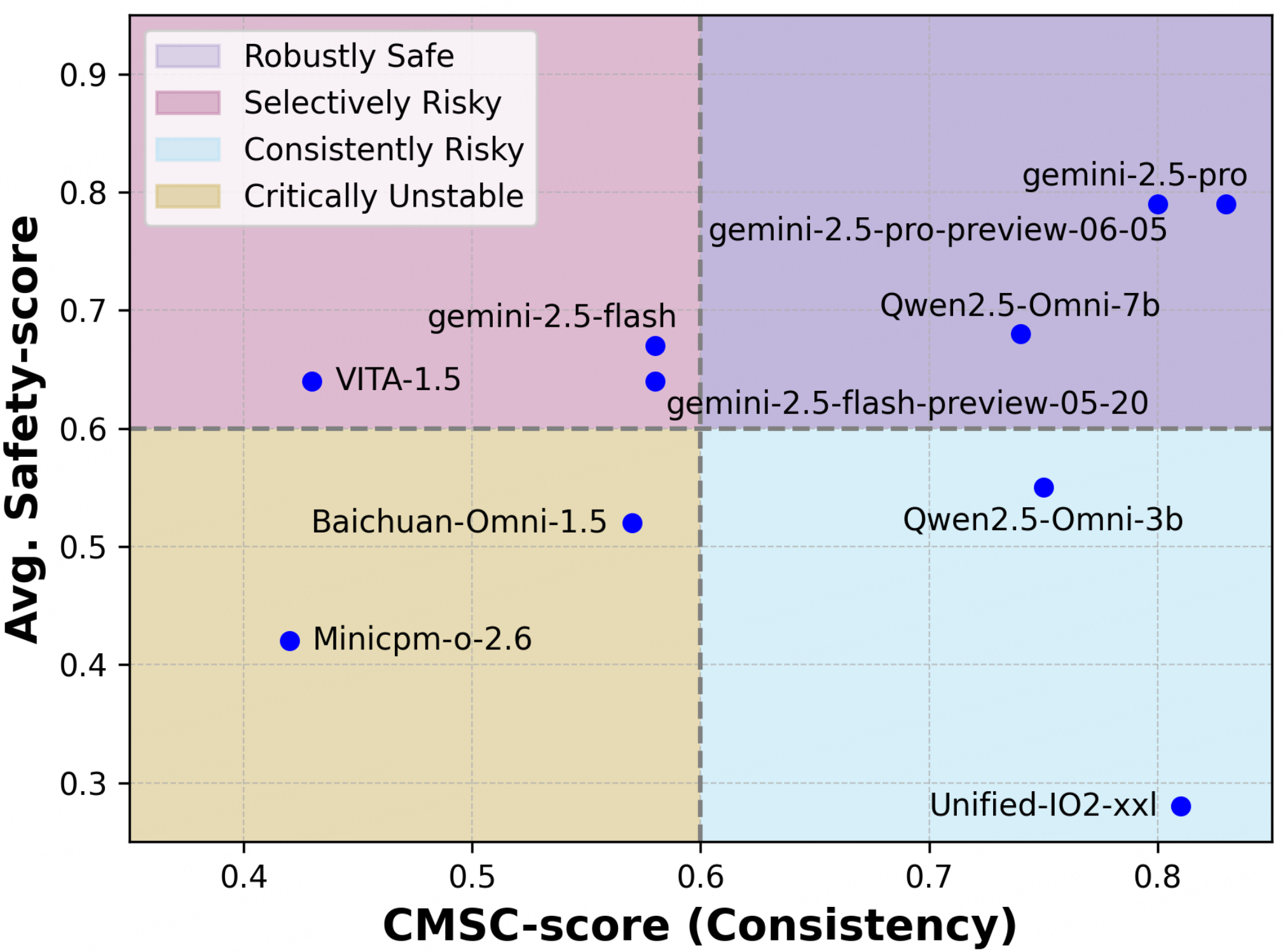
Leyi Pan, Zheyu Fu, Yunpeng Zhai, Shuchang Tao, Sheng Guan, Shiyu Huang, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Felix Henry, Lijie Wen, Aiwei Liu
arXiv:2508.07173, 2025


[PDF] [Code] [Dataset] [BibTeX]
@misc{pan2025omnisafetybenchbenchmarksafetyevaluation, title={Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models}, author={Leyi Pan and Zheyu Fu and Yunpeng Zhai and Shuchang Tao and Sheng Guan and Shiyu Huang and Lingzhe Zhang and Zhaoyang Liu and Bolin Ding and Felix Henry and Lijie Wen and Aiwei Liu}, year={2025}, eprint={2508.07173}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2508.07173}, }
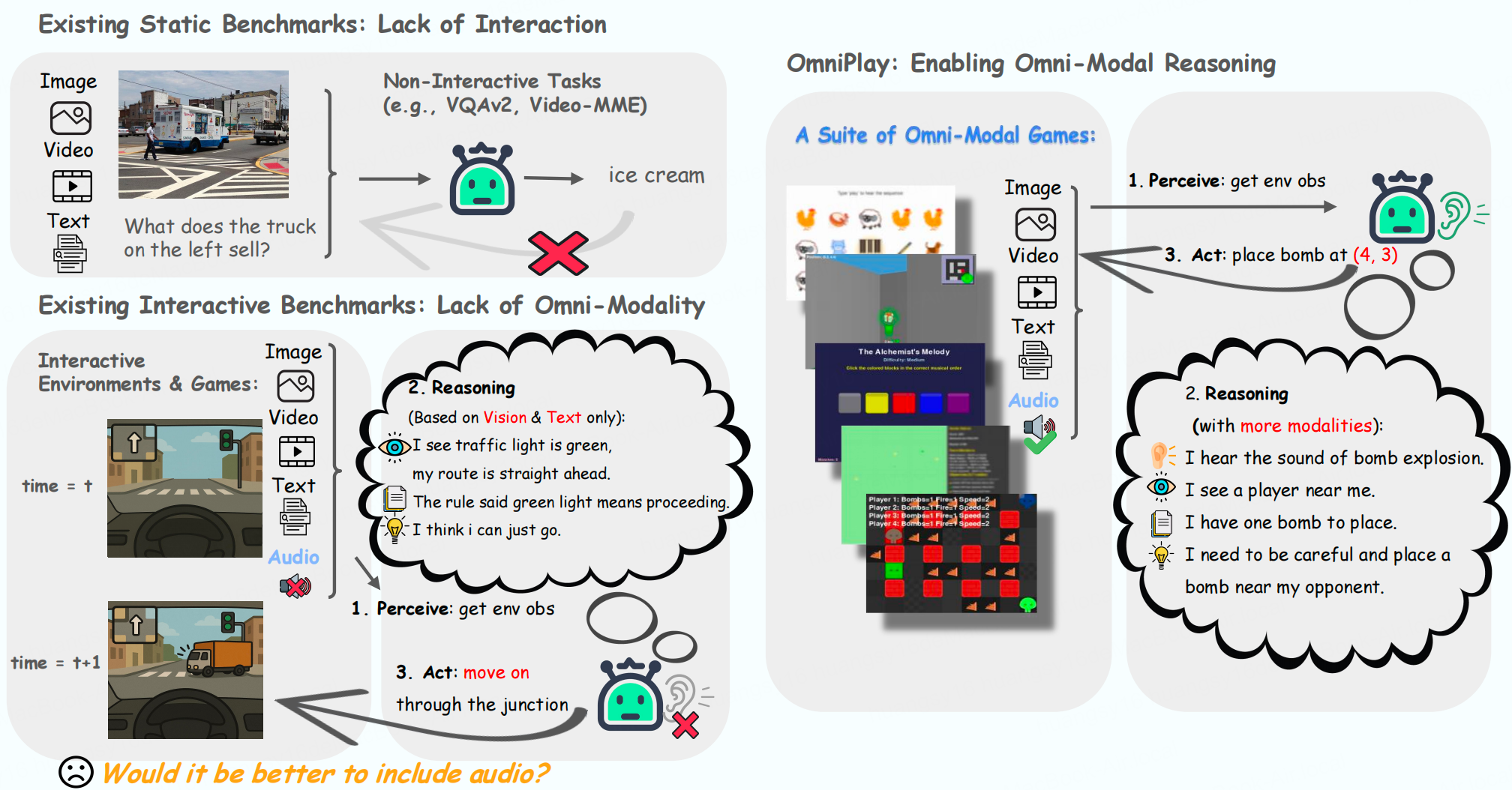
Fuqing Bie, Shiyu Huang, Xijia Tao, Zhiqin Fang, Leyi Pan, Junzhe Chen, Min Ren, Liuyu Xiang, Zhaofeng He
arXiv:2508.04361, 2025


[PDF] [Code] [BibTeX]
@article{bie2025omniplay, title={OmniPlay: Benchmarking Omni-Modal Models on Omni-Modal Game Playing}, author={Bie, Fuqing and Huang, Shiyu and Tao, Xijia and Fang, Zhiqin and Pan, Leyi and Chen, Junzhe and Ren, Min and Xiang, Liuyu and He, Zhaofeng}, journal={arXiv preprint arXiv:2508.04361}, year={2025} }
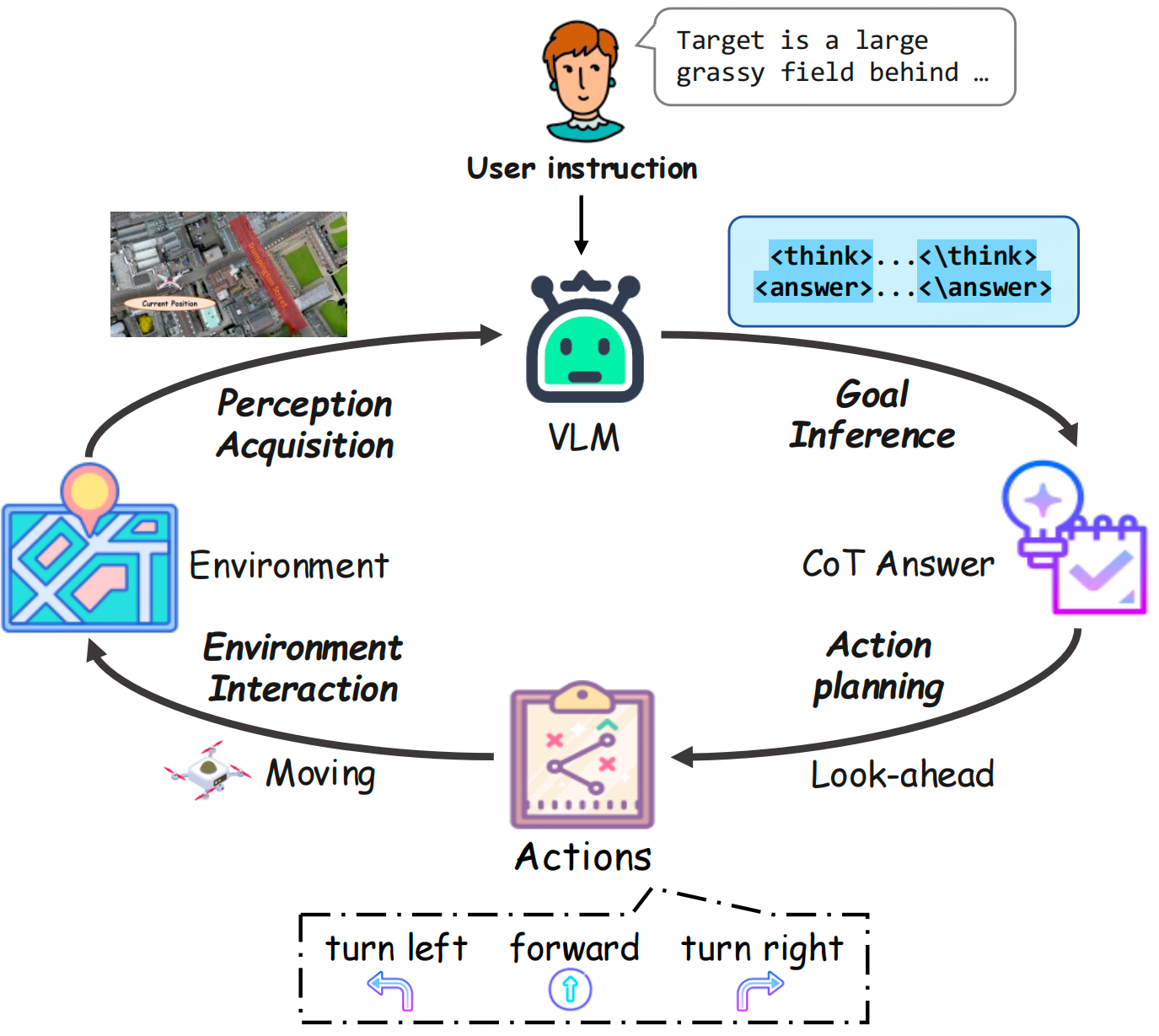
Hengxing Cai*, Jinhan Dong*, Yijie Rao*, Jingcheng Deng, Jingjun Tan, Qien Chen, Haidong Wang, Zhen Wang, Shiyu Huang, Agachai Sumalee, Renxin Zhong
arXiv:2508.00390, 2025
[PDF] [BibTeX]
@article{cai2025sa, title={SA-GCS: Semantic-Aware Gaussian Curriculum Scheduling for UAV Vision-Language Navigation}, author={Cai, Hengxing and Dong, Jinhan and Rao, Yijie and Deng, Jingcheng and Tan, Jingjun and Chen, Qien and Wang, Haidong and Wang, Zhen and Huang, Shiyu and Sumalee, Agachai and others}, journal={arXiv preprint arXiv:2508.00390}, year={2025} }
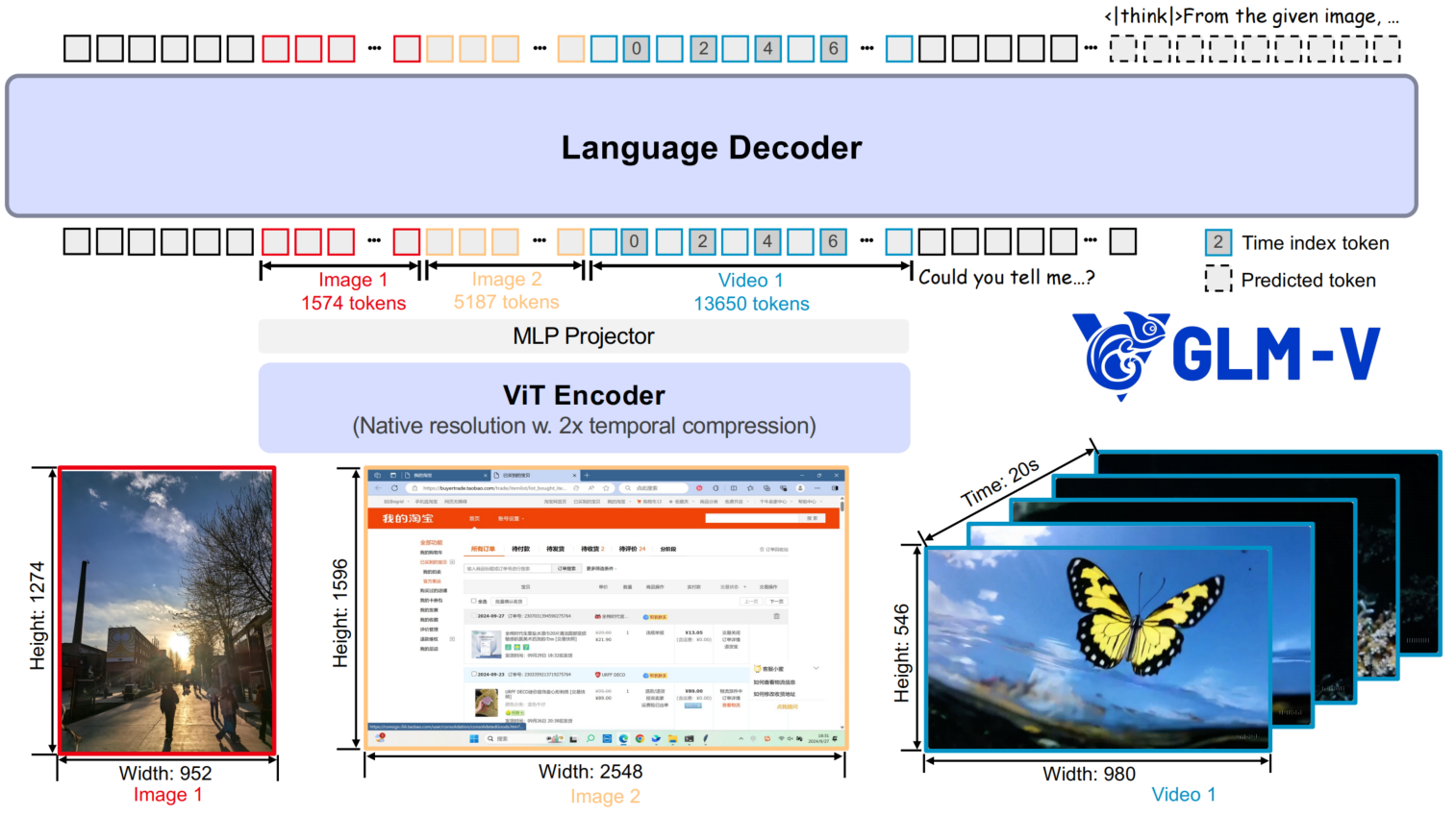
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiali Chen, Jing Chen, Jinhao Chen, Jinghao Lin, Jinjiang Wang, Junjie Chen, Leqi Lei, Letian Gong, Leyi Pan, Mingzhi Zhang, Qinkai Zheng, Sheng Yang, Shi Zhong, Shiyu Huang, Shuyuan Zhao, Siyan Xue, Shangqin Tu, Shengbiao Meng, Tianshu Zhang, Tianwei Luo, Tianxiang Hao, Wenkai Li, Wei Jia, Xin Lyu, Xuancheng Huang, Yanling Wang, Yadong Xue, Yanfeng Wang, Yifan An, Yifan Du, Yiming Shi, Yiheng Huang, Yilin Niu, Yuan Wang, Yuanchang Yue, Yuchen Li, Yutao Zhang, Yuxuan Zhang, Zhanxiao Du, Zhenyu Hou, Zhao Xue, Zhengxiao Du, Zihan Wang, Peng Zhang, Debing Liu, Bin Xu, Juanzi Li, Minlie Huang, Yuxiao Dong, Jie Tang
arXiv:2507.01006, 2025


[PDF] [Code] [BibTeX]
@article{hong2025glm, title={GLM-4.1 V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning}, author={Hong, Wenyi and Yu, Wenmeng and Gu, Xiaotao and Wang, Guo and Gan, Guobing and Tang, Haomiao and Cheng, Jiale and Qi, Ji and Ji, Junhui and Pan, Lihang and others}, journal={arXiv preprint arXiv:2507.01006}, year={2025} }
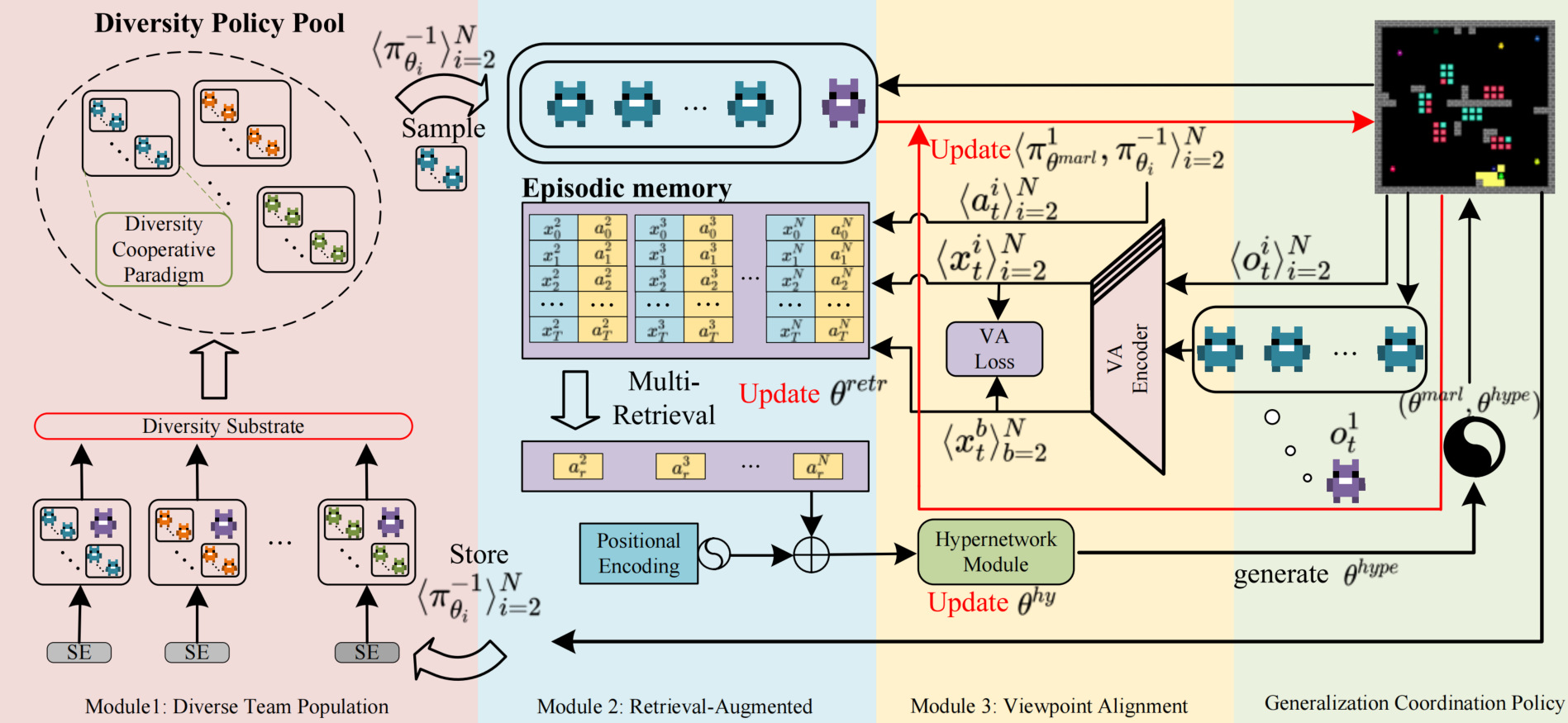
Chenxu Wang, Yonggang Jin, Cheng Hu, Youpeng Zhao, Zipeng Dai, Jian Zhao, Shiyu Huang, Liuyu Xiang, Junge Zhang, Zhaofeng He
Neurocomputing (2025): 130912


[PDF] [Code] [BibTeX]
@article{wang2025generalizable, title={Generalizable Agent Modeling for Agent Collaboration-Competition Adaptation with Multi-Retrieval and Dynamic Generation}, author={Wang, Chenxu and Jin, Yonggang and Hu, Cheng and Zhao, Youpeng and Dai, Zipeng and Zhao, Jian and Xiang, Liuyu and Zhang, Junge and He, Zhaofeng}, journal={Neurocomputing}, pages={130912}, year={2025}, publisher={Elsevier} }

Wenyi Hong*, Yean Cheng*, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, Jie Tang
The IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2025


[Blog] [PDF] [Code] [Dataset] [Leaderboard] [BibTeX]
@article{hong2025motionbench, title={MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models}, author={Hong, Wenyi and Cheng, Yean and Yang, Zhuoyi and Wang, Weihan and Wang, Lefan and Gu, Xiaotao and Huang, Shiyu and Dong, Yuxiao and Tang, Jie}, journal={arXiv preprint arXiv:2501.02955}, year={2025} }
-
Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?
Leyi Pan, Aiwei Liu, Shiyu Huang, Yijian Lu, Xuming Hu, Lijie Wen, Irwin King, Philip S. Yu
The 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
[PDF] [Code] [BibTeX]@article{pan2025can, title={Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?}, author={Pan, Leyi and Liu, Aiwei and Huang, Shiyu and Lu, Yijian and Hu, Xuming and Wen, Lijie and King, Irwin and Yu, Philip S}, journal={arXiv preprint arXiv:2502.11598}, year={2025} }
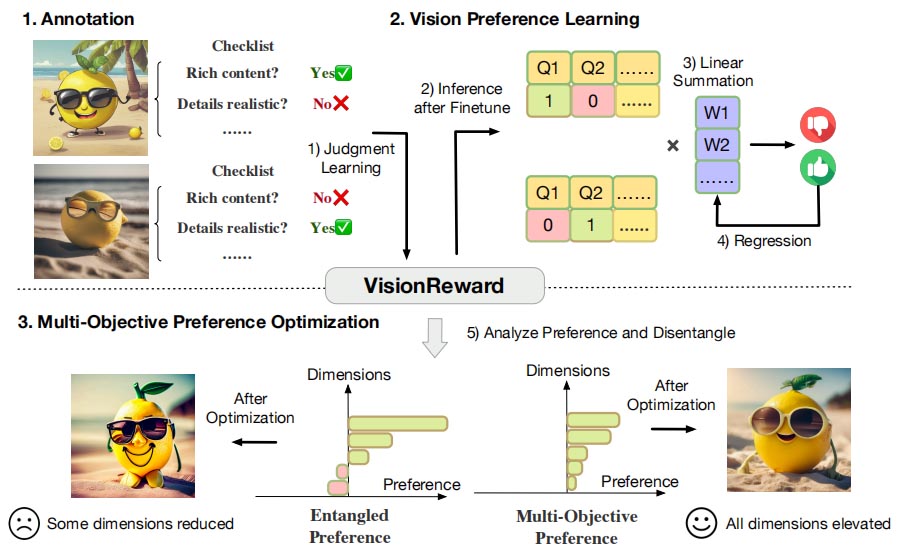
Jiazheng Xu*, Yu Huang*, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, Jiayan Teng, Zhuoyi Yang, Wendi Zheng, Xiao Liu, Ming Ding, Xiaohan Zhang, Xiaotao Gu, Shiyu Huang, Minlie Huang, Jie Tang, Yuxiao Dong
The Fortieth AAAI Conference on Artificial Intelligence(AAAI), 2026


[PDF] [Code] [Huggingface] [BibTeX]
@article{xu2024visionreward, title={VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation}, author={Xu, Jiazheng and Huang, Yu and Cheng, Jiale and Yang, Yuanming and Xu, Jiajun and Wang, Yuan and Duan, Wenbo and Yang, Shen and Jin, Qunlin and Li, Shurun and others}, journal={arXiv preprint arXiv:2412.21059}, year={2024} }
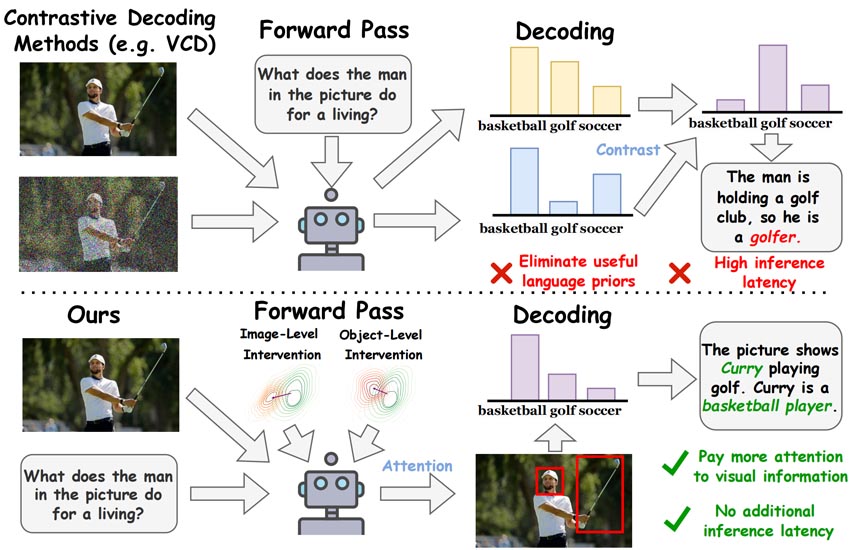
Junzhe Chen*, Tianshu Zhang*, Shiyu Huang, Yuwei Niu, Linfeng Zhang, Lijie Wen, Xuming Hu
The IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2025
[PDF] [BibTeX]
@article{chen2024ict, title={ICT: Image-Object Cross-Level Trusted Intervention for Mitigating Object Hallucination in Large Vision-Language Models}, author={Chen, Junzhe and Zhang, Tianshu and Huang, Shiyu and Niu, Yuwei and Zhang, Linfeng and Wen, Lijie and Hu, Xuming}, journal={arXiv preprint arXiv:2411.15268}, year={2024} }

Yean Cheng*, Ziqi Cai*, Ming Ding, Wendi Zheng, Shiyu Huang, Yuxiao Dong, Jie Tang, Boxin Shi
arXiv:2411.01602, 2024
[PDF] [BibTeX]
@article{cheng2024dreampolish, title={DreamPolish: Domain Score Distillation With Progressive Geometry Generation}, author={Cheng, Yean and Cai, Ziqi and Ding, Ming and Zheng, Wendi and Huang, Shiyu and Dong, Yuxiao and Tang, Jie and Shi, Boxin}, journal={arXiv preprint arXiv:2411.01602}, year={2024} }
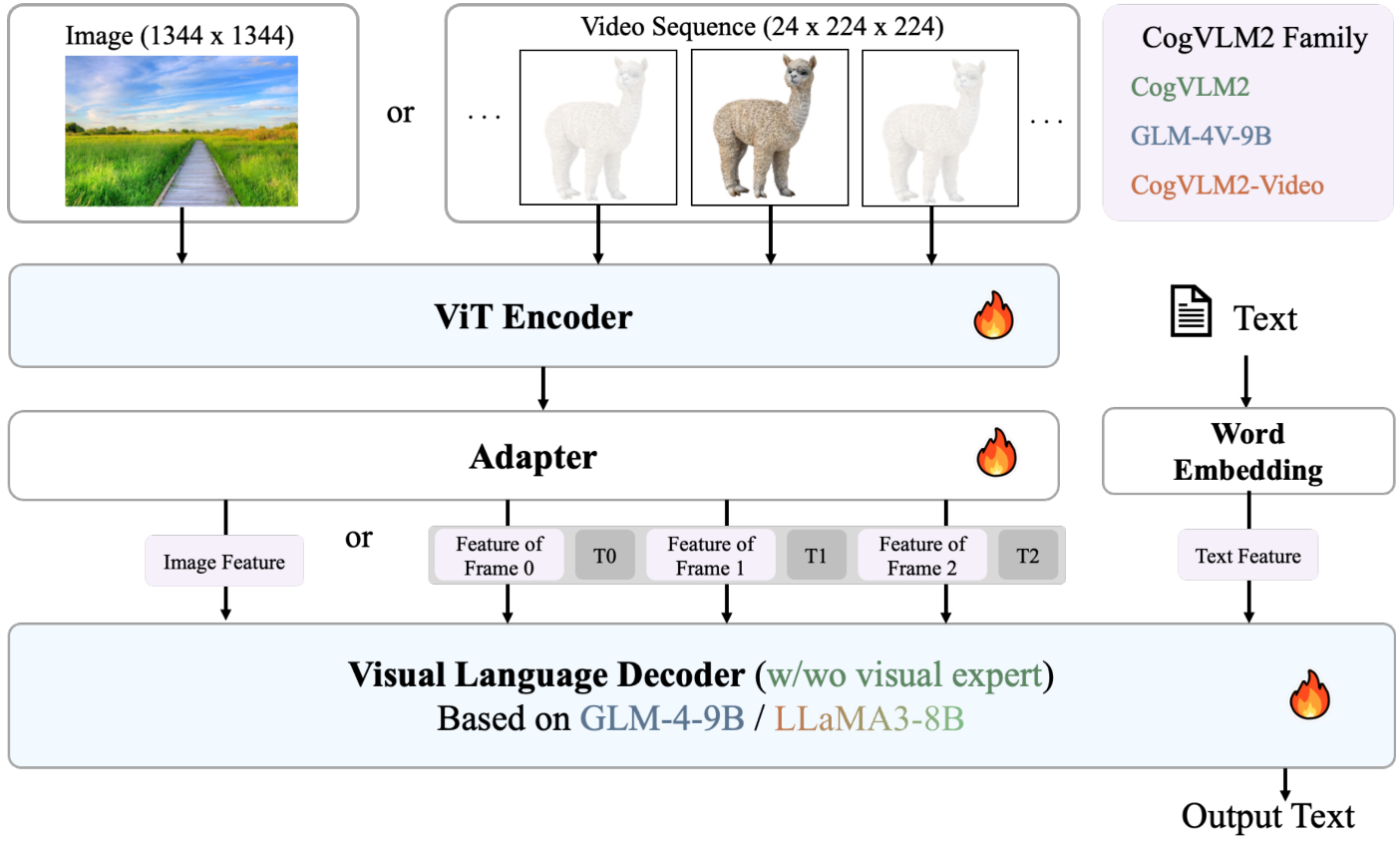
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, Zhao Xue, Lei Zhao, Zhuoyi Yang, Xiaotao Gu, Xiaohan Zhang, Guanyu Feng, Da Yin, Zihan Wang, Ji Qi, Xixuan Song, Peng Zhang, Debing Liu, Bin Xu, Juanzi Li, Yuxiao Dong, Jie Tang
arXiv:2408.16500, 2024


[PDF] [Code] [Huggingface] [BibTeX]
@article{hong2024cogvlm2, title={CogVLM2: Visual Language Models for Image and Video Understanding}, author={Hong, Wenyi and Wang, Weihan and Ding, Ming and Yu, Wenmeng and Lv, Qingsong and Wang, Yan and Cheng, Yean and Huang, Shiyu and Ji, Junhui and Xue, Zhao and others}, journal={arXiv preprint arXiv:2408.16500}, year={2024} }

Zhuoyi Yang*, Jiayan Teng*, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Xiaohan Zhang, Xiaotao Gu, Guanyu Feng, Da Yin, Wenyi Hong, Weihan Wang, Yean Cheng, Yuxuan Zhang, Ting Liu, Bin Xu, Yuxiao Dong, Jie Tang
The Thirteenth International Conference on Learning Representations (ICLR), 2025


[PDF] [Code] [Huggingface] [BibTeX]
@article{yang2024cogvideox, title={CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer}, author={Yang, Zhuoyi and Teng, Jiayan and Zheng, Wendi and Ding, Ming and Huang, Shiyu and Xu, Jiazheng and Yang, Yuanming and Hong, Wenyi and Zhang, Xiaohan and Feng, Guanyu and others}, journal={arXiv preprint arXiv:2408.06072}, year={2024} }
-
WaterSeeker: Pioneering Efficient Detection of Watermarked Segments in Large Documents
Leyi Pan, Aiwei Liu, Yijian Lu, Zitian Gao, Yichen Di, Shiyu Huang, Lijie Wen, Irwin King, Philip S. Yu
The AAAI 2025 PDLM Workshop on Preventing and Detecting LLM Misinformation, 2025
[PDF] [Code] [BibTeX]@misc{pan2025waterseekerpioneeringefficientdetection, title={WaterSeeker: Pioneering Efficient Detection of Watermarked Segments in Large Documents}, author={Leyi Pan and Aiwei Liu and Yijian Lu and Zitian Gao and Yichen Di and Shiyu Huang and Lijie Wen and Irwin King and Philip S. Yu}, year={2025}, eprint={2409.05112}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2409.05112}, }
-
A Survey on Self-play Methods in Reinforcement Learning
Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, Yu Wang
arXiv:2408.01072, 2024
[PDF] [BibTeX]@misc{zhang2024surveyselfplaymethodsreinforcement, title={A Survey on Self-play Methods in Reinforcement Learning}, author={Ruize Zhang and Zelai Xu and Chengdong Ma and Chao Yu and Wei-Wei Tu and Shiyu Huang and Deheng Ye and Wenbo Ding and Yaodong Yang and Yu Wang}, year={2024}, eprint={2408.01072}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2408.01072}, } -
Soft-QMIX: Integrating Maximum Entropy For Monotonic Value Function Factorization
Wentse Chen, Shiyu Huang, Jeff Schneider
arXiv:2406.13930, 2024
[PDF] [Code] [BibTeX]@misc{chen2024softqmixintegratingmaximumentropy, title={Soft-QMIX: Integrating Maximum Entropy For Monotonic Value Function Factorization}, author={Wentse Chen and Shiyu Huang and Jeff Schneider}, year={2024}, eprint={2406.13930}, archivePrefix={arXiv}, primaryClass={cs.LG} url={https://arxiv.org/abs/2406.13930}, }
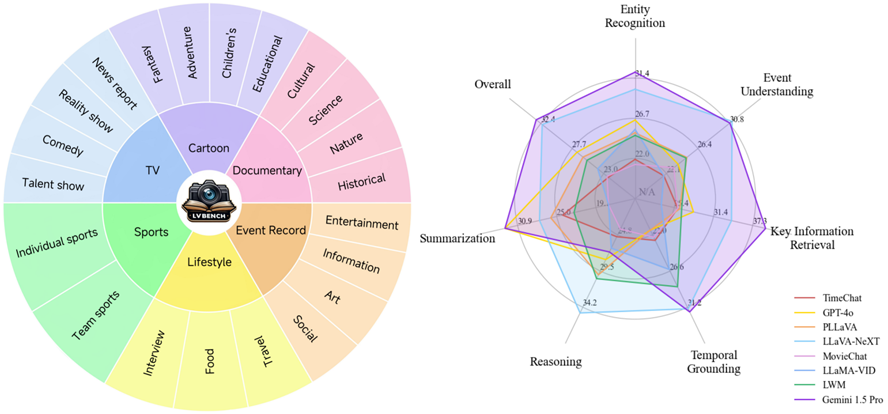
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, Jie Tang
International Conference on Computer Vision(ICCV)(Highlight), 2025

[PDF] [Project] [Code] [Huggingface] [BibTeX]
@misc{wang2024lvbench, title={LVBench: An Extreme Long Video Understanding Benchmark}, author={Weihan Wang and Zehai He and Wenyi Hong and Yean Cheng and Xiaohan Zhang and Ji Qi and Shiyu Huang and Bin Xu and Yuxiao Dong and Ming Ding and Jie Tang}, year={2024}, eprint={2406.08035}, archivePrefix={arXiv}, primaryClass={cs.CV} }
-
MQE: Unleashing the Power of Interaction with Multi-agent
Quadruped Environment
Ziyan Xiong, Bo Chen, Shiyu Huang, Wei-Wei Tu, Zhaofeng He, Yang Gao
The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
[PDF] [Code] [BibTeX]@misc{xiong2024mqeunleashingpowerinteraction, title={MQE: Unleashing the Power of Interaction with Multi-agent Quadruped Environment}, author={Ziyan Xiong and Bo Chen and Shiyu Huang and Wei-Wei Tu and Zhaofeng He and Yang Gao}, year={2024}, eprint={2403.16015}, archivePrefix={arXiv}, primaryClass={cs.RO}, url={https://arxiv.org/abs/2403.16015}, } -
LLMArena: Assessing Capabilities of Large Language Models in
Dynamic Multi-Agent Environments
Junzhe Chen, Xuming Hu, Shuodi Liu, Shiyu Huang, Wei-Wei Tu, Zhaofeng He, Lijie Wen
The 62nd Annual Meeting of the Association for Computational Linguistics(ACL), 2024
-
AutoSAT: Automatically Optimize SAT Solvers via Large Language
Models
Yiwen Sun, Xianyin Zhang, Shiyu Huang, Shaowei Cai, Bing-Zhen Zhang, Ke Wei
arXiv:2402.10705, 2024
-
OpenRL: A Unified Reinforcement Learning Framework
Shiyu Huang, Wentse Chen, Yiwen Sun, Fuqing Bie, Wei-Wei Tu
arXiv:2312.16189, 2023
[PDF] [Code] [BibTeX]@article{huang2023openrl, title={OpenRL: A Unified Reinforcement Learning Framework}, author={Huang, Shiyu and Chen, Wentse and Sun, Yiwen and Bie, Fuqing and Tu, Wei-Wei}, journal={arXiv preprint arXiv:2312.16189}, year={2023} } -
DGPO: Discovering Multiple Strategies with
Diversity-Guided Policy Optimization
Wenze Chen, Shiyu Huang, Yuan Chiang, Tim Pearce, Wei-Wei Tu, Ting Chen, Jun Zhu
Thirty-Eighth AAAI Conference on Artificial Intelligence(AAAI), Vancouver, Canada, 2024
-
SwiftSage: A Generative Agent with Fast and Slow Thinking for
Complex Interactive Tasks
Bill Yuchen Lin, Yicheng Fu, Karina Yang, Prithviraj Ammanabrolu, Faeze Brahman, Shiyu Huang, Chandra Bhagavatula, Yejin Choi, Xiang Ren
Thirty-seventh Conference on Neural Information Processing Systems(NeurIPS)(Spotlight), 2023
-
Robustness and Generalizability of Deepfake Detection: A Study
with Diffusion Models
Haixu Song, Shiyu Huang, Yinpeng Dong, Wei-Wei Tu
arXiv:2309.02218, 2023
-
Diverse Policies Converge in Reward-free Markov Decision
Processes
Fanqi Lin, Shiyu Huang, Wei-Wei Tu
The 20th Pacific Rim International Conference on Artificial Intelligence(PRICAI), Jakarta, Indonesia, 2023
-
Uncertainty quantification via a memristor
Bayesian deep neural network for risk-sensitive reinforcement learning
Yudeng Lin, Qingtian Zhang, Bin Gao, Jianshi Tang, Peng Yao, Chongxuan Li, Shiyu Huang, Zhengwu Liu, Ying Zhou, Yuyi Liu, Wenqiang Zhang, Jun Zhu and He Qian
Nature Machine Intelligence, 2023
-
TiZero: Mastering Multi-Agent Football with Curriculum Learning
and Self-Play
Fanqi Lin*, Shiyu Huang*, Tim Pearce, Wenze Chen and Wei-Wei Tu
The 22nd International Conference on Autonomous Agents and Multiagent Systems(AAMAS), London, UK, 2023
-
Learning Graph-Enhanced Commander-Executor for Multi-Agent
Navigation
Xinyi Yang, Shiyu Huang, Yiwen Sun, Yuxiang Yang, Chao Yu, Wei-Wei Tu, Huazhong Yang and Yu Wang
The 22nd International Conference on Autonomous Agents and Multiagent Systems(AAMAS), London, UK, 2023
-
DGPO: Discovering Multiple Strategies with
Diversity-Guided Policy Optimization
Wenze Chen, Shiyu Huang, Yuan Chiang, Ting Chen, Jun Zhu
The 22nd International Conference on Autonomous Agents and Multiagent Systems(AAMAS) Extended Abstract, London, UK, 2023
-
VMAPD: Generate Diverse
Solutions for Multi-Agent Games with Recurrent Trajectory Discriminators
Shiyu Huang*, Chao Yu*, Bin Wang, Dong Li, Yu Wang, Ting Chen and Jun Zhu
IEEE Conference on Games(COG)(Best Paper Nomination), Beijing, China, 2022
-
Ranking Cost: Building An Efficient and Scalable
Circuit Routing Planner with Evolution-Based Optimization
Shiyu Huang, Bin Wang, Dong Li, Jianye Hao, Ting Chen and Jun Zhu
IJCAI-ECAI 2022 Workshop: The 2nd International Workshop on Heuristic Search in Industry, Vienna, Austria, 2022
-
TiKick: Towards Playing Multi-agent Football Full
Games from Single-agent Demonstrations
Shiyu Huang*, Wenze Chen*, Longfei Zhang, Shizhen Xu, Ziyang Li, Fengming Zhu, Deheng Ye, Ting Chen and Jun Zhu
NeurIPS-21 Workshop: 2nd Offline Reinforcement Learning Workshop
-
Deep
Reinforcement Learning with Credit Assignment for Combinatorial Optimization
Dong Yan, Jiayi Weng, Shiyu Huang, Chongxuan Li, Yichi Zhou, Hang Su, Jun Zhu
Pattern Recognition, 2021
-
Off-Policy Training
for Truncated TD(λ) Boosted Soft Actor-Critic
Shiyu Huang, Bin Wang, Hang Su, Dong Li, Jianye Hao, Jun Zhu, Ting Chen
The 18th Pacific Rim International Conference on Artificial Intelligence(PRICAI), Hanoi, Vietnam, 2021
-
SVQN: Sequential Variational Soft
Q-Learning Networks
Shiyu Huang, Hang Su, Jun Zhu, and Ting Chen
Eighth International Conference on Learning Representations (ICLR), Millennium Hall, Addis Ababa ETHIOPIA, 2020
-
Combo-Action: Training Agent For
FPS Game with Auxiliary Tasks (Spotlight)
Shiyu Huang, Hang Su, Jun Zhu, and Ting Chen
The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI), Honolulu, Hawaii, USA, 2019
-
Expecting the Unexpected:
Training Detectors for Unusual Pedestrians with Adversarial Imposters
Shiyu Huang, and Deva Ramanan
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, USA, 2017
-
Learning to Assign Credit in
Reinforcement Learning by Incorporating Abstract Relations
Dong Yan, Shiyu Huang, Hang Su, and Jun Zhu
AAAI-19 Workshop on Reinforcement Learning in Games
-
Model-based Credit Assignment for Model-free Deep
Reinforcement Learning
Dong Yan, Jiayi Weng, Shiyu Huang, Chongxuan Li, Yichi Zhou, Hang Su, Jun Zhu


Talks
Projects
-
CogVideoX
-
CogVLM2-Video
-
OpenRL: Unified reinforcement learning
framework.
-
TiZero: RL agents for Google Research
Football.
- ChatAgent: A Python-based agent framework for large language models.
- TLaunch: Launch programs on multiple hosts.
- OpenPlugin: Toolkit to manage the plugins of the large language model.



Patents
- Generation method, device, medium and computing device of diversity strategy. Shiyu Huang, Tian Tian. 2021116684627
- Method or equipment for controlling agent. Jun Zhu, Shiyu Huang, Hang Su. ZL201910078546.1
Honors & Awards
- Tung OOCL Scholarship, Tsinghua University, 2019
- Tsinghua Excellent Graduates, Tsinghua University, 2017
- Academic Excellence Award, Tsinghua University, 2014-2016
Competitions
-
2022.8
IEEE CoG 2022 Football AI Competition:
Track2, 3rd place
-
2018.8
ViZDoom 2018 AI Competition:
Track1, 1st place
Track2, 2nd place
-
2017
ViZDoom 2017 AI Competition:
Track2, 2nd place
Services
Organizer for:NeurIPS 2023 Workshop on New in ML
Reviewer for:
AAAI 2026, NeurIPS 2025, ICCV 2025, ICML 2025, CVPR 2025, ICLR 2025, AAAI 2025, NeurIPS 2024, ICML 2024, ICLR 2024, AAAI 2024, NeurIPS 2023, AISTATS 2023, AAAI 2023, ICLR 2023, NeurIPS 2022, ICML 2022, AISTATS 2022, AAAI 2022, ICLR 2022, NeurIPS 2021, ICML 2021, AAAI 2021, NeurIPS 2020
Teaching
2020 Spring, TA in Big Data and Machine Intelligence, instructed by Zhen Chen
2019 Fall, TA in Big Data and Machine Intelligence, instructed by Zhen Chen
2019 Spring, TA in Machine Learning, instructed by Prof. Jun Zhu